Performance
Pre-computed feeds
-
Async
-
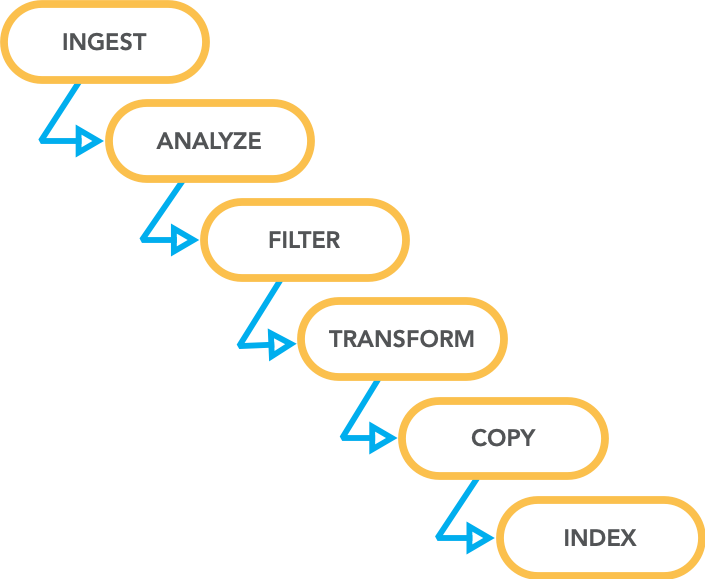
Yupdates has a fleet of servers and serverless functions dedicated to asynchronous processing, from polling to filtering to transforming. We do everything ahead of time and behind the scenes to make the interactive experience snappy, even if it means making extra copies of data for the sake of faster queries.
-
Comprehensive
-
One of our core tenets is to be fast for all feeds at all timestamps. If you go looking into the past, it shouldn't feel like a hard drive is spinning up somewhere. It should feel as fast as browsing the latest. It takes a lot to deliver this. Rust services and heavily optimized DynamoDB queries are the foundation.
Databases
-
DynamoDB
-
Few databases in the world can handle petabytes of data and leave you confident there won't be performance surprises or unpredictable costs. AWS says single-digit millisecond performance at any scale, and that's been our experience.
We love the consistency. Often, chasing better peak performance with other databases leaves a long tail of unhappy outliers, especially as you scale.
-
PostgreSQL
-
Our web/API layer leaves most of the work to the backend Rust services and DynamoDB, but it relies on a Postgres cluster.
-
Caches
-
Over-provisioned cache clusters let us avoid many database queries, making the service even faster.
Scaling
-
Serverful
-
We do use serverless functions for asynchronous work, but interactive and API traffic is served by our fleet of Graviton2 instances behind a load balancer for lower, more consistent latency.
-
That pesky speed of light
-
Today, Yupdates runs in the US East (Ohio) region of AWS. We're comfortable expanding when it makes sense.
What's that mean for you? Feed queries need one HTTP GET, as static assets are usually cached in your browser. It takes 50 milliseconds or less for the servers to process the request, so most of our customers see a complete feed page load in 100-300 milliseconds. But, in faraway places, the extra transit time may mean it takes 2-3x longer — not the best it could be, but still a second or less.
The best way to see how it works for you is to try it out for free.
-
Cost model
-
A significant portion of your subscription goes towards our well-provisioned server fleet, cache clusters, and databases.
Instead of relying on ad revenue and its perverse incentives, the unit economics of each subscription covers the additional load. We're able to buy premium resources and keep buying them as we grow.